We’ll assume all columns in our data have been normalized - with zero mean and unit standard deviation.
Eigenvalue decomposition
For any square matrix , is an eigenvector of and the corresponding eigenvalue of if . Suppose has a full set of independent eigenvectors (most matrices do, but not all).
If we put the eigenvectors into a matrix (the eigenvectors are the column vectors of the matrix), then , where is a diagonal matrix, with the eigenvalues on the diagonal. Thus
This is the Eigenvalue Decomposition: a square matrix () which is diagonalizable can be factorized as:
where is the square matrix whose th column is the eigenvector of , and is the diagonal matrix whose diagonal elements are the corresponding eigenvalues. is square and orthogonal (), because the eigenvectors are orthogonal.
SVD (Singular Value Decomposition)
If is not square we need a different decomposition. Suppose is an matrix ( rows and columns) - then we need a square, orthogonal matrix to multiply on the right, and a square, orthogonal matrix to multiply on the left. In which case our matrix (say A) can be factorized as:
will then be an matrix where the subset will be diagonal with singular values and the remaining entries will be zero.
We have
Note that this is a sum of matrices. The first is the best rank 1 approximation to ; the first is the best rank approximation to
PCA decomposition
The PCA decomposition requires that one compute the eigenvalues and eigenvectors of the covariance matrix of (again an matrix), which is the product . Since the covariance matrix is symmetric, the matrix is diagonalizable, and the eigenvectors can be normalized such that they are orthonormal.
The square corvariance matrix () is symmetric and thus diagonizable, and so from equation (Equation 1), it can be factorized as:
where is the diagonal matrix with the eigenvalues of the covariance matrix and has column vectors that are the eigenvectors of the covariance matrix.
However, using the SVD (Equation 2) we can also write
Using the SVD to perform PCA makes much better sense numerically than forming the covariance matrix to begin with, since the formation of can cause loss of precision.
For a positive semi-definite matrix SVD and eigendecomposition are equivalent. PCA boils down to the eigendecomposition of the covariance matrix. Finding the maximum eigenvalue(s) and corresponding eigenvector(s) can be thought of as finding the direction of maximum variance.
If we have a lot of data (many rows or many columns or both), we’ll have a large covariance matrix and large number of eigenvalues and their corresponding eigenvectors (though there can be duplicates).
Do we need them all? How many are just due to noise or measurement error? First look at random matrices, then at covariance matrices formed from random matrices.
Random Matrices
Let’s perform an experiment, generating a large random data set using measurements.
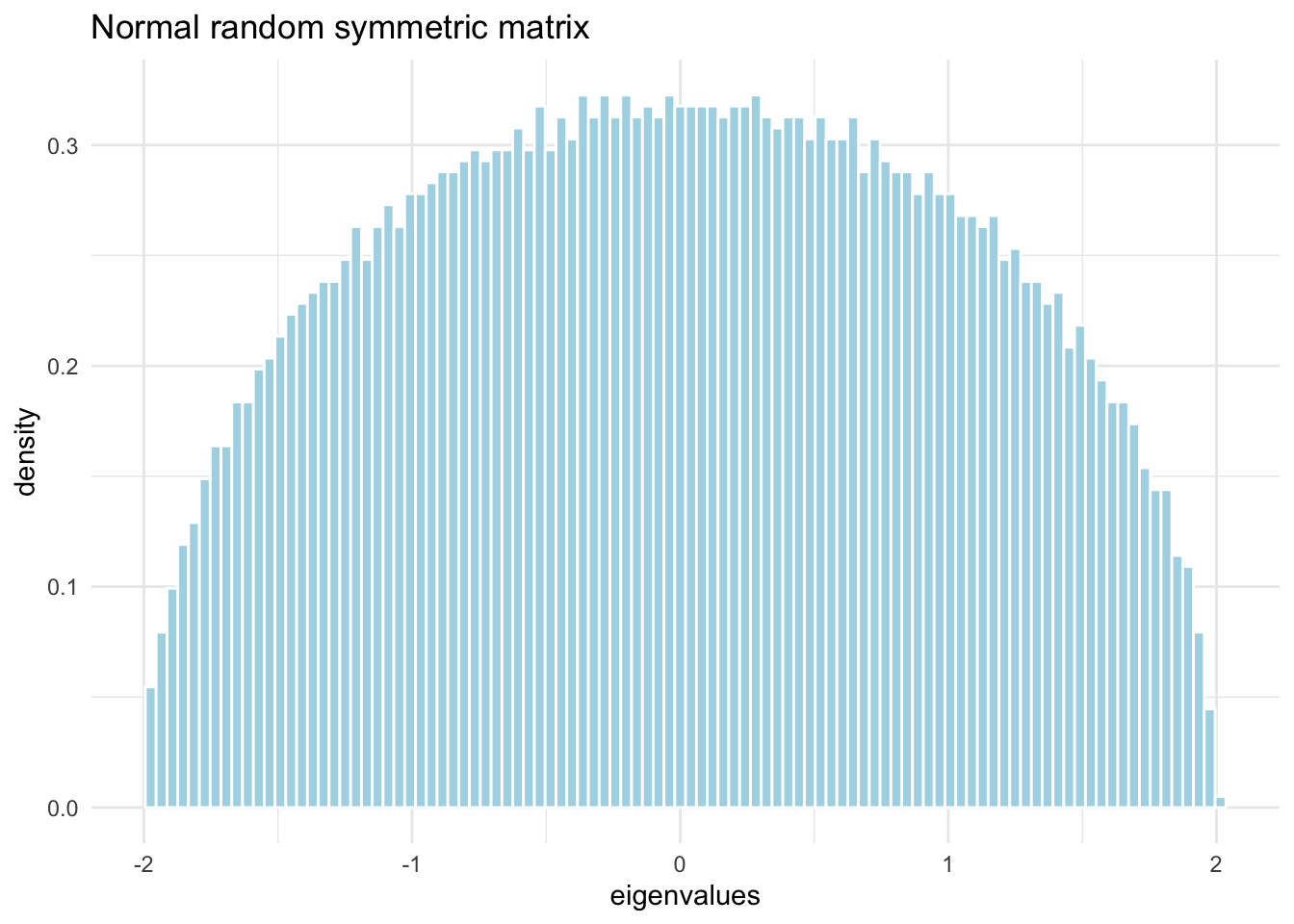
eigenvalues from random symmetric matrix (Normally distributed measurements)
require(ggplot2, quietly=TRUE)# 5000 rows and columnsn <-5000# generate n^2 samples from N(0,1)m <-array( rnorm(n^2) ,c(n,n))# make it symmetricm2 <- (m +t(m))/sqrt(2*n) # t(m) %*% m# compute eigenvalues and vectorslambda <-eigen(m2, symmetric=T, only.values = T)# plot the eignevaluestibble::tibble(lambda = lambda$values) |>ggplot(aes(x = lambda, y =after_stat(density))) +geom_histogram(color ="white", fill="lightblue", bins=100) +labs(x ='eigenvalues', title ='Normal random symmetric matrix') +theme_minimal()
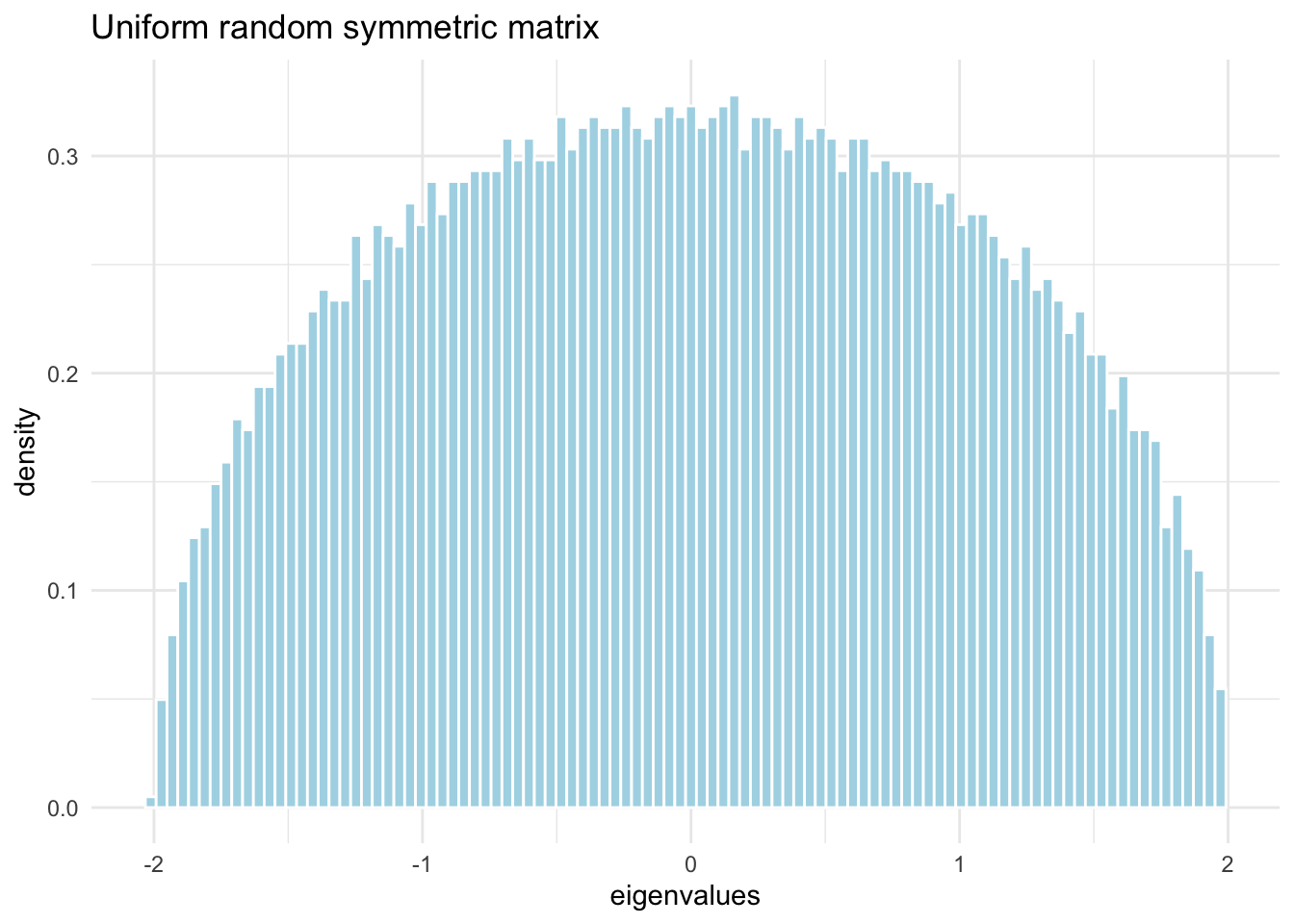
Let’s do the same, but with uniform distributed measurements.
eigenvalues from random symmetric matrix (Uniformly distributed measurements)
# 5000 rows and columnsn <-5000# generate n^2 samples from U(0,1)m <-array( runif(n^2) ,c(n,n))# make it symmetricm2 <-sqrt(12)*(m +t(m) -1)/sqrt(2*n) # t(m) %*% m# compute eigenvalues and vectorslambda <-eigen(m2, symmetric=T, only.values = T)# plot the eignevaluestibble::tibble(lambda = lambda$values) |>ggplot(aes(x = lambda, y =after_stat(density))) +geom_histogram(color ="white", fill="lightblue", bins=100) +labs(x ='eigenvalues', title ='Uniform random symmetric matrix') +theme_minimal()
Note the striking pattern: the density of eigenvalues is a semicircle.
Wigner’s semicircle law
Let be an matrix with entries . Define
then is symmetric with variance
and the density of the eigenvalues of is given by
which, as shown by Wigner, as
Random correlation matrices
We have variables with rows. The elements of the empirical correlation matrix are given by:
where denotes the -th (normalized) value of variable . This can be written as where is the dataset.
Assuming the values of are random with variance then in the limit , while keeping the ratio constant, the density of eigenvalues of is given by
where the minimum and maximum eigenvalues are given by
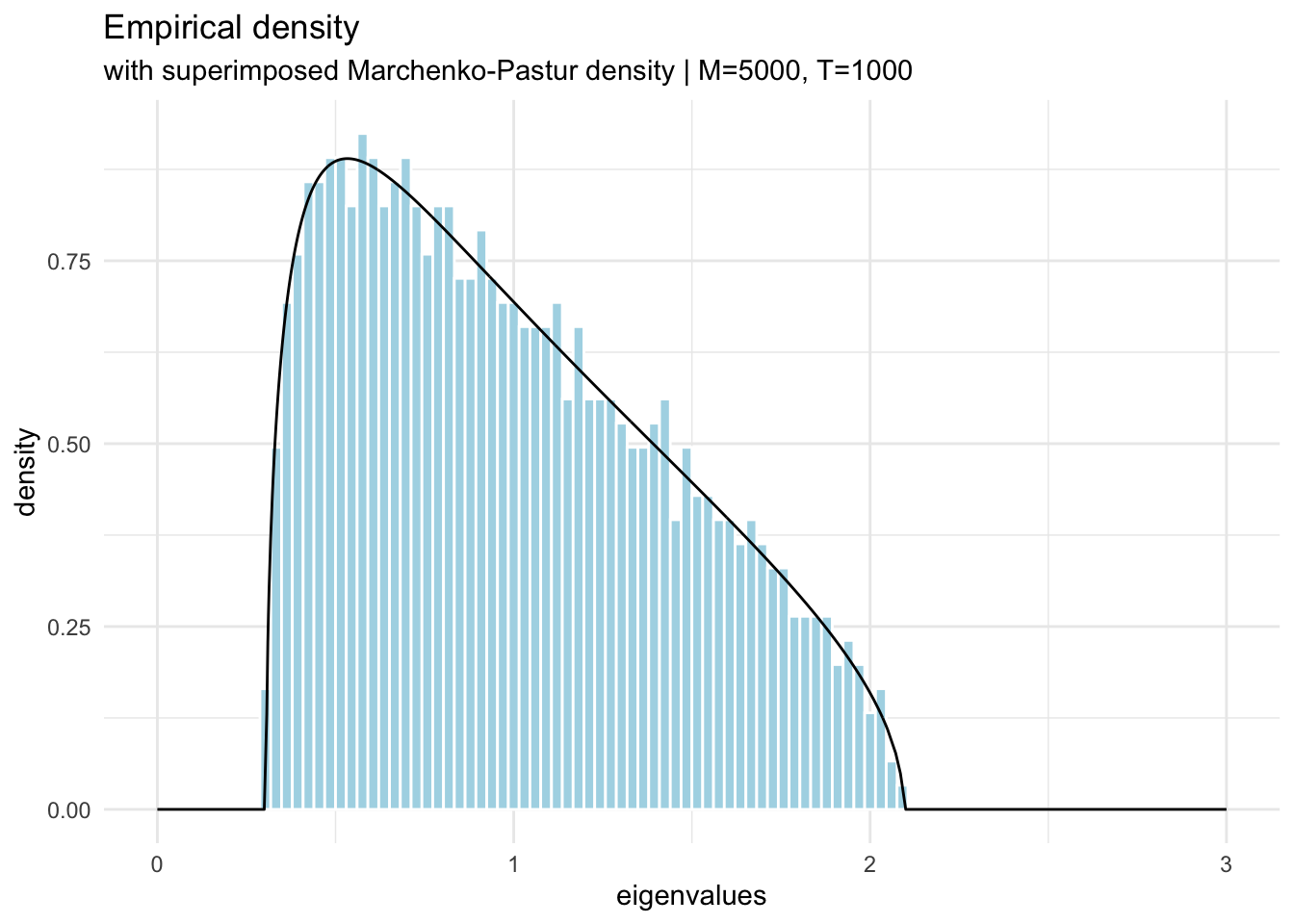
is also known as the Marchenko-Pastur distribution that describes the asymptotic behavior of eigenvalues of large random correlation matrices.
t <-5000;m <-1000;h =array(rnorm(m*t),c(m,t)); # Time series in rowse = h %*%t(h)/t; # Form the correlation matrixlambdae =eigen(e, symmetric=TRUE, only.values =TRUE);# create the mp distributionmpd_tbl <- tibble::tibble(lambda =c(lambdae$values, seq(0,3,0.1)) ) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m)))# plot the eigenvaluestibble::tibble(lambda = lambdae$values) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m))) |>ggplot(aes(x = lambda, y =after_stat(density))) +geom_histogram(color ="white", fill="lightblue", bins=100) +geom_line(data = mpd_tbl, aes(y=mp_dist)) +labs(x ='eigenvalues', title ='Empirical density' , subtitle = stringr::str_glue("with superimposed Marchenko-Pastur density | M={t}, T={m}") ) +xlim(0,3) +theme_minimal()
Code
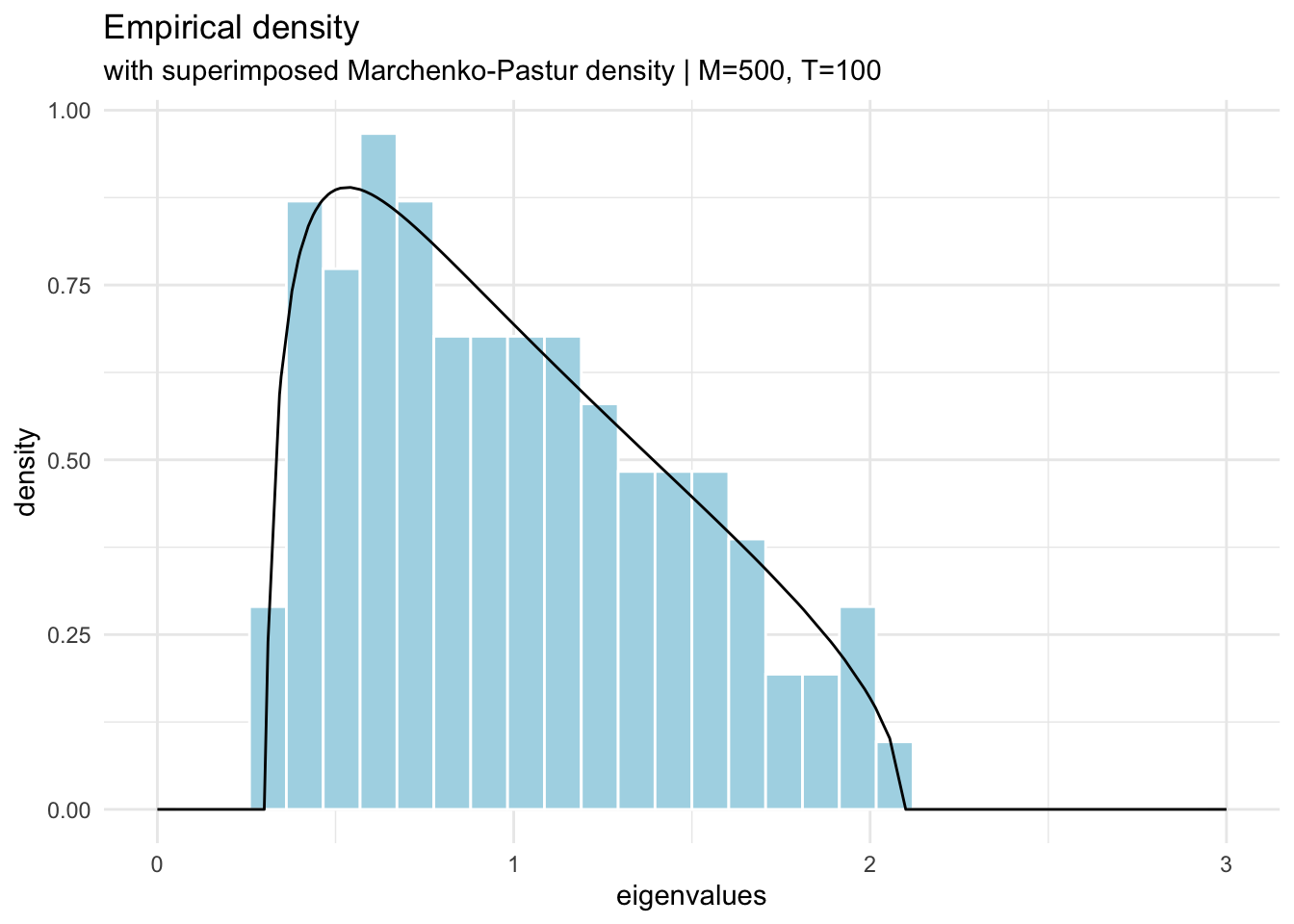
t <-500;m <-100;h =array(rnorm(m*t),c(m,t)); # Time series in rowse = h %*%t(h)/t; # Form the correlation matrixlambdae =eigen(e, symmetric=T, only.values = T);# create the mp distributionmpd_tbl <- tibble::tibble(lambda =c(lambdae$values, seq(0,3,0.1)) ) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m)))# plot the eigenvaluestibble::tibble(lambda = lambdae$values) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m))) |>ggplot(aes(x = lambda, y =after_stat(density))) +geom_histogram(color ="white", fill="lightblue", bins=30) +geom_line(data = mpd_tbl, aes(y=mp_dist)) +labs(x ='eigenvalues', title ='Empirical density' , subtitle = stringr::str_glue("with superimposed Marchenko-Pastur density | M={t}, T={m}") ) +xlim(0,3) +theme_minimal()
Code
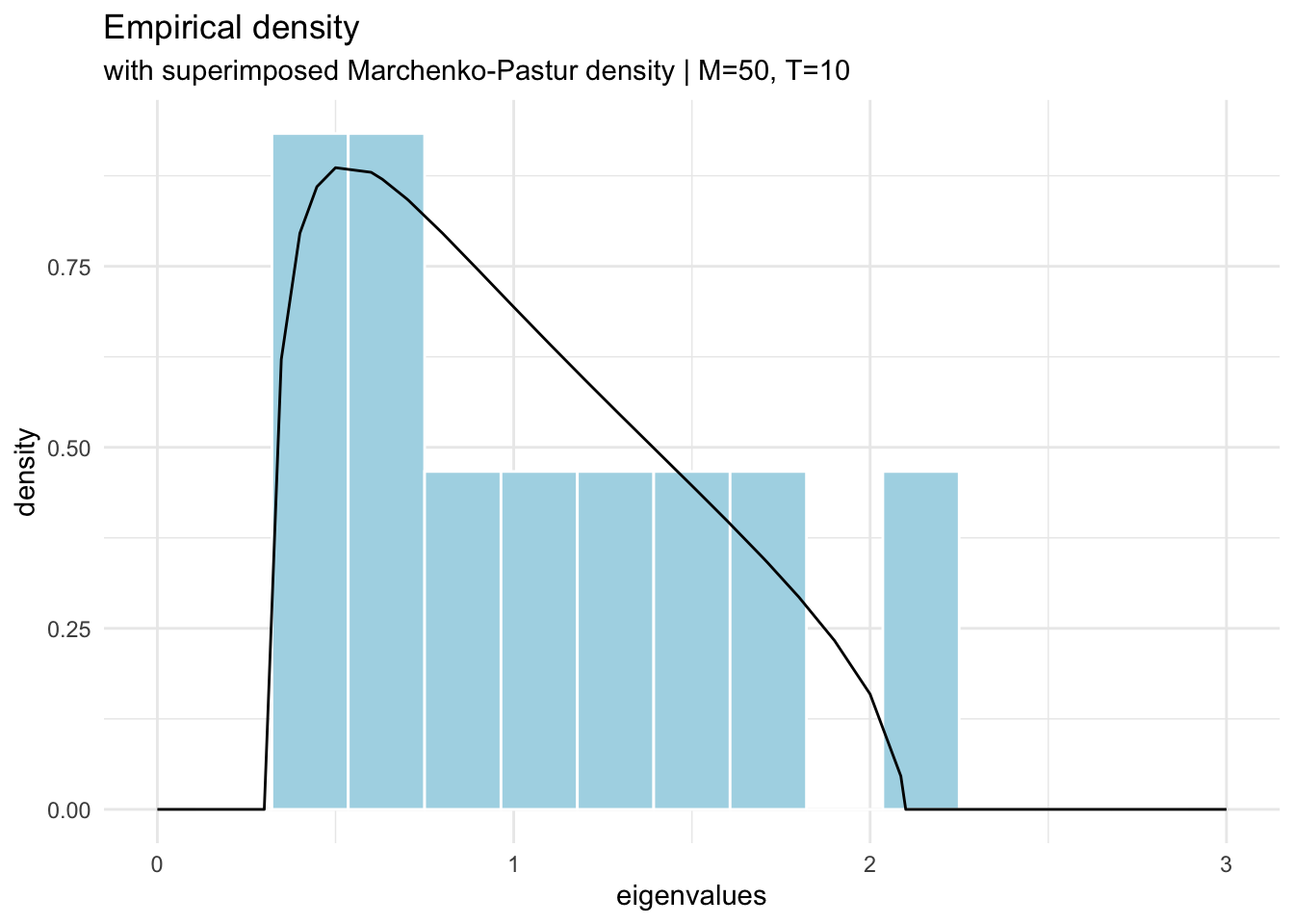
t <-50;m <-10;h =array(rnorm(m*t),c(m,t)); # Time series in rowse = h %*%t(h)/t; # Form the correlation matrixlambdae =eigen(e, symmetric=T, only.values = T);# create the mp distributionmpd_tbl <- tibble::tibble(lambda =c(lambdae$values, seq(0,3,0.1)) ) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m)))# plot the eigenvaluestibble::tibble(lambda = lambdae$values) |> dplyr::mutate(mp_dist = purrr::map_dbl(lambda, ~mpd(lambda = ., t,m))) |>ggplot(aes(x = lambda, y =after_stat(density))) +geom_histogram(color ="white", fill="lightblue", bins=15) +geom_line(data = mpd_tbl, aes(y=mp_dist)) +labs(x ='eigenvalues', title ='Empirical density' , subtitle = stringr::str_glue("with superimposed Marchenko-Pastur density | M={t}, T={m}") ) +xlim(0,3) +theme_minimal()
Application to correlation matrices
For the special case of correlation matrices (e.g. PCA), we know that and . This bounds the probability mass over the interval defined by .
Since this distribution describes the spectrum of random matrices with mean 0, the eigenvalues of correlation matrices (read PCA component weights) that fall inside of the aforementioned interval could be considered spurious or noise. For instance, obtaining a correlation matrix of 10 variables with 252 observations would render
Thus, out of 10 eigenvalues/components of said correlation matrix, only the values higher than 1.43 would be considered significantly different from random.