Regression methods
BSMM8740-2-R-2024F [WEEK - 3]
Recap of last lecture
Last time we worked with the
recipespackage to develop workflows for pre-processing our data.Today we look at regression methods we might apply to understand relationships between measurements in our data.
Linear regression
Linear regression models
In the simple linear regression (SLR) model, we have \(N\) observations of a single outcome variable \(Y\) along with \(D\) predictor (aka co-variate) variables \(\mathbf{x}\) where the likelihood1 of observing \(Y=y\) is conditional on the predictor values \(x\) and parameters \(\theta=\{\beta,\sigma^2\}\):
\[ \pi\left(Y=y|\mathbf{x,\theta}\right)=\mathscr{N}\left(\left.y\right|\mu(\mathbf{x};\beta),\sigma^{2}\right) \]
Linear regression models
In the SLR model, \(\mathscr{N}\left(\left.y\right|\mu(\mathbf{x};\beta),\sigma^{2}\right)\) is a Normal probability density with mean \(\mu(\mathbf{x};\beta)\) and variance \(\sigma^2\), where \(\sigma^2\) is a constant and the mean is a function of the predictors \(\mathbf{x}\) and a vector of parameters \(\beta\).
The mean function \(\mu(\mathbf{x};\beta)\) is often assumed to be continuous, i.e. a small change in the predictors implies a small change in the outcome. In addition, it is often convenient to decompose the mean function into a sum of simpler functions, e.g. polynomial functions (like straight lines, parabolas, and more).
Taylor Series
The decomposition of a function \(f\) of a single variable \(x\) into a sum of simpler polynomial functions is called a Taylor series and is defined as follows:
\[ f(x;x_0)=\sum_{n=0}\beta_n(x-x_0)^n=\beta_0+\beta_1(x-x_0)+\beta_2(x-x_0)^2+\beta_3(x-x_0)^3+\ldots \]
where \(\frac{d^nf(x)}{dx^n}|_{x=x_0} \equiv f^{(n)}(x_0) = n!\beta_n\;\rightarrow \beta_n=\frac{1}{n!}f^{(n)}(x_0)\)
Taylor Series
\[ f(x;x_0)=\sum_n\beta_n(x-x_0)^n=\beta_0+\beta_1(x-x_0)+\beta_2(x-x_0)^2+\beta_3(x-x_0)^3+\ldots \]
We can use the following constructive proof to find the coefficients in the series:
- \(0^{th}\) derivative at \(x=x_0\): \(f(x_0) = \beta_0\)
- \(1^{st}\) derivative at \(x=x_0\): \(f'(x_0) = \beta_1\)
- \(2^{nd}\) derivative at \(x=x_0\): \(f''(x_0) = 2\beta_2\)
- \(3^{rd}\) derivative at \(x=x_0\): \(f'''(x_0) = 6\beta_3\)
- \(n^{th}\) derivative at \(x=x_0\): \(f^{(n)}(x_0) = n!\beta_n\)
Linear regression models
Similarly, when the number of variables is \(D=2\) the Taylor series is (writing \(f_{x}\equiv\frac{\partial f}{\partial x}\), \(f_{y}\equiv\frac{\partial f}{\partial y}\), \(f_{x,y}\equiv\frac{\partial^2 f}{\partial x,\partial x}\) and so on):
\[ \begin{align*} f(x,y;x_0,y_0) & =f(x_{0},y_{0})+f_{x}(x_{0},y_{0})(x-x_{0})+f_{y}(x_{0},y_{0})(y-y_{0})\\ & = + \frac{1}{2}f_{x,x}(x_{0},y_{0})(x-x_{0})^{2}+\frac{1}{2}f_{y,y}(x_{0},y_{0})(y-y_{0})^{2}\\ & = + \frac{1}{2}f_{x,y}(x_{0},y_{0})(x-x_{0})(y-y_{0})+\ldots \end{align*} \]
which decomposes a function of two variables into a sum of simpler functions, e.g. polynomial functions (like 2-D straight lines, parabolas, and more).
Linear regression models
For one co-variate, if the mean function is smooth (i.e. not changing rapidly with the co-variate) then \(\mu^{(n)}\) will be decreasing in \(n\), and furthermore \(\beta_n\) decreases as \(1/n!\), so SLR models in one co-variate typically use only the first two or at most three \(\beta\) coefficients.
Thus the likelihood of observing \(Y=y\) is conditional on the predictor values \(x\) and parameters \(\theta=\{\beta_0,\beta_1,\sigma^2\}\):
\(\theta=\{\beta_{0},\mathbf{\beta},\sigma^{2}\}\) are the parameters of the model, where \(\beta_0\) is a constant and \(\beta_1\) is the co-variate weight or regression coefficient.
Linear regression models
For multiple co-variates, If the mean function is smooth (i.e. not changing rapidly with the co-variates) then under similar (reasonable) assumptions on the differentials, it is common to see SLR models using only the first order coefficients, i.e. a constant and one coefficient for each co-variate.
Linear regression models
Note
It is common to add the unit constant to the covariate vector \(x=(1,x_1,x_2,\ldots)\) so that the coefficient vector is \(\mathbf{\beta}=(\beta_0,\beta_{x_1},\beta_{x_2},\ldots)\), and the model can be expressed1 as a vector equation: \(y=\mathbf{\beta}\cdot \mathbf{x}\).
Linear regression models
Recall that the one dimensional Normal/Gaussian probability density (aka likelihood) is:
\[ \mathscr{N}\left(x;\mu,\sigma^2\right)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{\frac{1}{2}\frac{x-\mu}{\sigma^2}} \]
The likelihood of multiple observations is the product of the likelihoods for each observation.
Linear regression models
To fit the 1D linear regression model given \(N\) data samples, we minimize the negative log-likelihood (NLL) on the training set.
\[ \begin{align*} \text{NLL}\left(\beta,\sigma^{2}\right) & =-\sum_{n=1}^{N}\log\left[\left(\frac{1}{2\pi\sigma^{2}}\right)^{\frac{1}{2}}\exp\left(-\frac{1}{2\sigma^{2}}\left(y_{n}-\beta'x_{n}\right)^{2}\right)\right]\\ & =\frac{1}{2\sigma^{2}}\sum_{n=1}^{N}\left(y_{n}-\hat{y}_{n}\right)^{2}-\frac{N}{2}\log\left(2\pi\sigma^{2}\right) \end{align*} \]
where the predicted response is \(\hat{y}\equiv\beta'x_{n}\). This is also the maximum likelihood estimation (MLE) method.
Linear regression models
Minimizing the NLL by minimizing the residual sum of squares (RSS) is the same as minimizing
- the mean squared error \(\text{MSE}\left(\beta\right) = \frac{1}{N}\text{RSS}\left(\beta\right)\)
- the root mean squared error \(\text{RMSE}\left(\beta\right) = \sqrt{\text{MSE}\left(\beta\right)}\)
Aside: empirical risk minimization
The MLE can be generalized by replacing the NLL (\(\ell\left(y_{n},\theta;x_{n}\right)=-\log\pi\left(y_n|x_n,\theta\right)\)) with any other loss function to get
\[ \mathscr{L}\left(\theta\right)=\frac{1}{N}\sum_{n=1}^{N}\ell\left(y_{n},\theta;x_{n}\right) \]
This is known as the empirical risk minimization (ERM) - the expected loss taken with respect to the empirical distribution.
Linear regression models
Focusing on just the coefficients \(\beta\), the minimum NLL is (up to a constant) the minimum of the residual sum of squares (RSS)1 with coefficient estimates \(\hat\beta\) :
\[ \begin{align*}\text{RSS}\left(\beta\right) & =\frac{1}{2}\sum_{n=1}^{N}\left(y_{n}-\beta'x_{n}\right)^{2}=\frac{1}{2}\left\Vert y_{n}-\beta'x_{n}\right\Vert ^{2}\\ & =\frac{1}{2}\left(y_{n}-\beta'x_{n}\right)'\left(y_{n}-\beta'x_{n}\right)\\ \\ \end{align*} \]
Linear regression models
Ordinary least squares (OLS)
Note that, given the assumption that the data generation process is Normal/Gaussian, we can write our regression equation in terms of individual observations as
\[ y_i=\beta_0+\beta_1 x_i + u_i \]
where error term \(u_i\) is a sample from \(\mathscr{N}\left(0,\sigma^{2}\right)\) which in turn implies \(\mathbb{E}\left[u\right]=0;\;\mathbb{E}\left[\left.u\right|x\right]=0\)
The independence of the covariates and the errors/residuals is a testable assumption.
Linear regression models
Ordinary least squares (OLS)
It follows independence of the covariates and the errors that
\[ \begin{align*} \mathbb{E}\left[y-\beta_{0}-\beta_{1}x\right] & =0\\ \mathbb{E}\left[x\left(y-\beta_{0}-\beta_{1}x\right)\right] & =0 \end{align*} \]
Linear regression models
Ordinary least squares (OLS)
Writing these equations in terms of our samples (where \(\hat{\beta}_{0}, \hat{\beta}_{1}\) are our coefficient estimates)
\[ \begin{align*} \frac{1}{N}\sum_{i-1}^{N}y_{i}-\hat{\beta}_{0}-\hat{\beta}_{1}x_{i} & =0\\ \frac{1}{N}\sum_{i-1}^{N}x_{i}\left(y_{i}-\hat{\beta}_{0}-\hat{\beta}_{1}x_{i}\right) & =0 \end{align*} \]
Linear regression models
Ordinary least squares (OLS)
From the first equation
\[ \begin{align*} \bar{y}-\hat{\beta}_{0}-\hat{\beta}_{1}\bar{x} & =0\\ \bar{y}-\hat{\beta}_{1}\bar{x} & =\hat{\beta}_{0} \end{align*} \]
Linear regression models
Ordinary least squares (OLS)
Substituting the expression for \(\hat{\beta}_{0}\) in the independence equation
\[ \begin{align*} \frac{1}{N}\sum_{i-1}^{N}x_{i}\left(y_{i}-\left(\bar{y}-\hat{\beta}_{1}\bar{x}\right)-\hat{\beta}_{1}x_{i}\right) & =0\\ \frac{1}{N}\sum_{i-1}^{N}x_{i}\left(y_{i}-\bar{y}\right) & =\hat{\beta}_{1}\frac{1}{N}\sum_{i-1}^{N}x_{i}\left(\bar{x}-x_{i}\right)\\ \frac{1}{N}\sum_{i-1}^{N}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right) & =\hat{\beta}_{1}\frac{1}{N}\sum_{i-1}^{N}\left(\bar{x}-x_{i}\right)^2 \end{align*} \]
Linear regression models
Ordinary least squares (OLS)
So as long as \(\sum_{i-1}^{N}\left(\bar{x}-x_{i}\right)^2\ne 0\)
\[ \begin{align*} \hat{\beta}_{1} & =\frac{\sum_{i-1}^{N}\left(x_{i}-\bar{x}\right)\left(y_{i}-\bar{y}\right)}{\sum_{i-1}^{N}\left(\bar{x}_{i}-x_{i}\right)^2}\\ & =\frac{\text{sample covariance}(x_{i}y_{i})}{\text{sample variance}(x_{i})} \end{align*} \]
Linear regression models
Similarly, in the vector equation, the minimum of the RSS is solved by (assuming \(N>D\)):
\[ \hat{\mathbf{\beta}}_{OLS}=\left(X'X\right)^{-1}\left(X'Y\right) = \frac{\text{cov}(X,Y)}{\text{var}(X)} \]
There are algorithmic issues with computing \(\left(X'X\right)^{-1}\) though, so we could instead start with \(X\beta=y\) and write \(\hat{\mathbf{\beta}}_{OLS}=X^{-1}y\) .
Linear regression algorithms
Computing the inverse of \(X'X\) directly, while theoretically possible, can be numerically unstable.
In R, the \(QR\) decomposition is used to solve for \(\beta\). Let \(X=QR\) where \(Q'Q=I\) and write:
\[ \begin{align*} (QR)\beta & = y\\ Q'QR\beta & = Q'y\\ \beta & = R^{-1}(Q'y) \end{align*} \]
Since \(R\) is upper triangular, the last equation can be solved by back-substitution.
Linear regression algorithms
[,1] [,2] [,3]
[1,] -0.1825742 -0.4082483 -8.944272e-01
[2,] -0.3651484 -0.8164966 4.472136e-01
[3,] -0.9128709 0.4082483 2.593051e-16Linear regression algorithms
Code
matrix A [,1] [,2] [,3]
[1,] 3 2.0 -1
[2,] 2 -2.0 4
[3,] -1 0.5 -1vector x[1] 1 -2 -2vector y [,1]
[1,] 1
[2,] -2
[3,] 0Linear regression algorithms
Collinearity
One of the important assumptions of the classical linear regression models is that there is no exact collinearity among the regressors.
While high correlation between regressors is a necessary indicator of the collinearity problem, a direct linear relationship beween regressors is sufficient.
Collinearity
Data collection methods, constraints on the fitted regression model, model specification error, an overdefined model, may be some potential sources of multicollinearity.
In other cases it is an artifact caused by creating new predictors from other predictors.
Collinearity
The problem of collinearity has potentially serious effect on the regression estimates such as:
- implausible coefficient signs,
- impossible inversion of matrix \(X'X\) as it becomes near or exactly singular,
- large magnitude of coefficients in absolute value,
- large variance or standard errors with wider confidence intervals.
Collinearity
Mitigating Collinearity:
- Remove Highly Correlated Variables: If two variables are highly correlated, consider removing one of them.
- Combine Variables: Create a new variable that combines the collinear variables
- Principal Component Analysis (PCA): Use PCA to transform the correlated variables into a smaller set of uncorrelated variables.
Bias vs Variance
We introduced truncated Taylor series approximations to motivate using simplified models of the mean function when using regression.
But bias is the error introduced by approximating a real-world problem, which may be complex, by a simplified model.
So to reduce bias, why not include more Taylor series terms, or more covariates in a first-order model?
Bias vs Variance
Note that for random variables in general and Gaussian random variables in particular
- the mean of the sum of random variables is the sum of the means of the random variables.
- the variance of the sum of random variables is the sum of the variances of the random variables.
So adding more terms or more covariates may reduce bias by improving the mean estimate, but will certainly increase the variance of the estimate.
Bias (B) vs Variance (V) tradeoffs
Low Bias and High Variance
- A model with low bias fits the training data very closely, capturing all the details and fluctuations.
- This leads to overfitting, where the model performs well on the training data but poorly on new data because it has learned the noise in the training data as if it were a signal.
High Bias and Low Variance
A model with high bias makes oversimplified assumptions about the data, ignoring relevant complexities.
This leads to underfitting, where the model is too simple to capture the underlying patterns in the data, resulting in poor performance on both training and new data.
Balancing Bias and Variance
- The goal is to find a sweet spot where the model is complex enough to capture the underlying patterns (low bias) but simple enough not to capture the noise (low variance).
- Achieving this balance ensures the model generalizes well to new data, providing good performance overall.
Bias (B) vs Variance (V) examples
Underfitting (High Bias, Low Variance)
- Suppose you’re predicting house prices using just the size of the house (one variable) in a linear regression model.
- If the true relationship is complex (e.g., non-linear, involving multiple factors), this simple model will have high bias and underfit the data, missing important patterns.
Overfitting (Low Bias, High Variance)
- Now, imagine you use a very complex model, like a high-degree polynomial regression, that uses many variables and interactions.
- This model fits the training data very well but captures noise as well. When applied to new data, its performance drops because it has learned patterns that don’t generalize (high variance).
Balanced Model
- A balanced model might use a moderate number of relevant variables and a reasonable complexity (like a linear regression with interaction terms or a low-degree polynomial).
- This model captures the essential patterns without fitting the noise, resulting in good generalization to new data.
Bias vs Variance
The following regression models techniques with the higher variance that follows from a large number of covariates by adding a bit of bias. The variance is reduced by penalizing covariate coefficients, shrinking then towards zero.
The resulting simpler models may not fully capture the patterns in the data, thus underfitting the data.
Ridge Regression
Ridge regression is an example of a penalized regression model; in this case the magnitude of the weights are penalized by adding the \(\ell_2\) norm of the weights to the loss function. In particular, the ridge regression weights are:
\[ \hat{\beta}_{\text{ridge}}=\arg\!\min\text{RSS}\left(\beta\right)+\lambda\left\Vert \beta\right\Vert _{2}^{2} \]
where \(\lambda\) is the strength of the penalty term.
The Ridge objective function is
\[ \mathscr{L}\left(\beta,\lambda\right)=\text{NLL}+\lambda\left\Vert \beta\right\Vert_2^2 \]
Ridge Regression
The solution is:
\[ \begin{align*} \hat{\mathbf{\beta}}_{ridge} & =\left(X'X-\lambda I_{D}\right)^{-1}\left(X'Y\right)\\ & =\left(\sum_{n}x_{n}x'_{n}+\lambda I_{D}\right)^{-1}\left(\sum_{n}y_{n}x_{n}\right) \end{align*} \]
Ridge Regression
As for un-penalized linear regression, using matrix inversion to solve for \(\hat{\mathbf{\beta}}_{ridge}\) can be a bad idea. The QR transformation can be used here, however, ridge regression is often used when \(D>N\), in which case the SVD transformation is faster.
Ridge Regression Example
Ridge Regression Example
Ridge Regression Example
glmnet example
> # perform k-fold cross-validation to find optimal lambda value
> cv_model <- glmnet::cv.glmnet(x, y, alpha = 0)
>
> # find optimal lambda value that minimizes test MSE
> best_lambda <- cv_model$lambda.min
>
> # produce plot of test MSE by lambda value
> cv_model %>% broom::tidy() %>%
+ ggplot(aes(x=lambda, y = estimate)) +
+ geom_ribbon(aes(ymin = conf.low, ymax = conf.high), fill = "#00ABFD", alpha=0.5) +
+ geom_point() +
+ geom_vline(xintercept=best_lambda) +
+ labs(title='Ridge Regression'
+ , subtitle =
+ stringr::str_glue(
+ "The best lambda value is {scales::number(best_lambda, accuracy=0.01)}"
+ )
+ ) +
+ ggplot2::scale_x_log10()
Ridge Regression Example
glmnet coefficients
> model$beta %>%
+ as.matrix() %>%
+ t() %>%
+ tibble::as_tibble() %>%
+ tibble::add_column(lambda = model$lambda, .before = 1) %>%
+ tidyr::pivot_longer(-lambda, names_to = 'parameter') %>%
+ ggplot(aes(x=lambda, y=value, color=parameter)) +
+ geom_line() + geom_point() +
+ xlim(0,2000) +
+ labs(title='Ridge Regression'
+ , subtitle =
+ stringr::str_glue(
+ "Parameters as a function of lambda"
+ )
+ )
Lasso Regression
Lasso regression is another example of a penalized regression model; in this case both the magnitude of the weights and the number of parameters are penalized by using the \(\ell_1\) norm of the weights to the loss function of the lasso regression. In particular, the lasso regression weights are:
\[ \hat{\beta}_{\text{lasso}}=\arg\!\min\text{RSS}\left(\beta\right)+\lambda\left\Vert \beta\right\Vert _{1} \]
The Lasso objective function is
\[ \mathscr{L}\left(\beta,\lambda\right)=\text{NLL}+\lambda\left\Vert \beta\right\Vert _{1} \]
Lasso Regression Example
lasso model
> # define response variable
> y <- mtcars %>% dplyr::pull(hp)
>
> # define matrix of predictor variables
> x <- mtcars %>% dplyr::select(mpg, wt, drat, qsec) %>% data.matrix()
>
> # fit ridge regression model
> model <- glmnet::glmnet(x, y, alpha = 1)
>
> # get coefficients when lambda = 3.53
> coef(model, s = 3.53)5 x 1 sparse Matrix of class "dgCMatrix"
s1
(Intercept) 480.761125
mpg -3.036337
wt 20.222451
drat .
qsec -18.944318Lasso Regression Example
lasso example
> #perform k-fold cross-validation to find optimal lambda value
> cv_model <- glmnet::cv.glmnet(x, y, alpha = 1)
>
> #find optimal lambda value that minimizes test MSE
> best_lambda <- cv_model$lambda.min
>
> #produce plot of test MSE by lambda value
> cv_model %>% broom::tidy() %>%
+ ggplot(aes(x=lambda, y = estimate)) +
+ geom_ribbon(aes(ymin = conf.low, ymax = conf.high), fill = "#00ABFD", alpha=0.5) +
+ geom_point() +
+ geom_vline(xintercept=best_lambda) +
+ labs(title='Lasso Regression'
+ , subtitle =
+ stringr::str_glue(
+ "The best lambda value is {scales::number(best_lambda, accuracy=0.01)}"
+ )
+ ) +
+ xlim(0,exp(4)) + ggplot2::scale_x_log10()
Lasso Regression Example
lasso coefficients
> model %>%
+ broom::tidy() %>%
+ tidyr::pivot_wider(names_from=term, values_from=estimate) %>%
+ dplyr::select(-c(step,dev.ratio, `(Intercept)`)) %>%
+ dplyr::mutate_all(dplyr::coalesce, 0) %>%
+ tidyr::pivot_longer(-lambda, names_to = 'parameter') %>%
+ ggplot(aes(x=lambda, y=value, color=parameter)) +
+ geom_line() + geom_point() +
+ xlim(0,70) +
+ labs(title='Ridge Regression'
+ , subtitle =
+ stringr::str_glue(
+ "Parameters as a function of lambda"
+ )
+ )
Elastic Net Regression
Elastic Net regression is a hybrid of ridge and lasso regression.
The elastic net objective function is
\[ \mathscr{L}\left(\beta,\lambda,\alpha\right)=\text{NLL}+\lambda\left(\left(1-\alpha\right)\left\Vert \beta\right\Vert _{2}^{2}+\alpha\left\Vert \beta\right\Vert _{1}\right) \]
so that \(\alpha=0\) is ridge regression and \(\alpha=1\) is lasso regression and \(\alpha\in\left(0,1\right)\) is the general elastic net.
Elastic Net Regression Example
elastic net example
> # set length of data and seed for reproducability
> n <- 50
> set.seed(2467)
> # create the dataset
> dat <- tibble::tibble(
+ a = sample(1:20, n, replace = T)/10
+ , b = sample(1:10, n, replace = T)/10
+ , c = sort(sample(1:10, n, replace = T))
+ ) %>%
+ dplyr::mutate(
+ z = (a*b)/2 + c + sample(-10:10, n, replace = T)/10
+ , .before = 1
+ )
> # cross validate to get the best alpha
> alpha_dat <- tibble::tibble( alpha = seq(0.01, 0.99, 0.01) ) %>%
+ dplyr::mutate(
+ mse =
+ purrr::map_dbl(
+ alpha
+ , (\(a){
+ cvg <-
+ glmnet::cv.glmnet(
+ x = dat %>% dplyr::select(-z) %>% as.matrix()
+ , y = dat$z
+ , family = "gaussian"
+ , gamma = a
+ )
+ min(cvg$cvm)
+ })
+ )
+ )
>
> best_alpha <- alpha_dat %>%
+ dplyr::filter(mse == min(mse)) %>%
+ dplyr::pull(alpha)
>
> cat("best alpha:", best_alpha)best alpha: 0.64elastic net example, part 2
best lambda: 0.01015384elastic net example, part 2
# A tibble: 4 × 5
term step estimate lambda dev.ratio
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) 1 -0.467 0.0102 0.963
2 a 1 0.221 0.0102 0.963
3 b 1 0.560 0.0102 0.963
4 c 1 1.03 0.0102 0.963Elastic Net Regression Example
elastic net example, part 3
RMSE: 0.5817823
R-squared: 0.9999828
MSE: 0.3384707
Generalized Linear Models
A generalized linear model (GLM) is a flexible generalization of ordinary linear regression.
Ordinary linear regression predicts the expected value of the outcome variable, a random variable, as a linear combination of a set of observed values (predictors). In a generalized linear model (GLM), each outcome \(Y\) is assumed to be generated from a particular distribution in an exponential family, The mean, \(\mu\), of the distribution depends on the independent variables, \(X\), through:
\[ \mathbb{E}\left[\left.Y\right|X\right]=\mu=\text{g}^{-1}\left(X\beta\right) \] where \(g\) is called the link function.
Generalized Linear Models
For example, if \(Y\) is Poisson distributed, then
\[ \mathbb{P}\left[\left.Y=y\right|X,\lambda\right]=\frac{\lambda^{y}}{y!}e^{-\lambda}=e^{y\log\lambda-\lambda-\log y!} \]
Where \(\lambda\) is both the mean and the variance. In the glm the link function is \(\log\) and
\[ \log\mathbb{E}\left[\left.Y\right|X\right] = \beta X=\log\lambda \]
Generalized Linear Models
Key Components of GLMs
Random Component:
- Specifies the probability distribution of the data generation process of the response variable (\(Y\)). Examples include Normal, Binomial, Poisson, etc.
Systematic Component:
- Specifies the linear predictor (\(\eta = X\beta)\), where (\(X\)) is the matrix of predictors and (\(\beta\)) is the vector of coefficients.
Link Function:
- Connects the mean of the response variable (\(\mathbb{E}(Y)\)) to the linear predictor (\(\eta\)). It transforms the expected value of the response variable to the linear predictor scale.
Generalized Linear Models
Common Types of GLMs
Linear Regression (Binomial Distribution)
- Response Variable: Continuous
- Link Function: Identity (\((g(\mu) = \mu\)))
- Example: Predicting house prices based on square footage, number of bedrooms, etc.
- Formula: \((Y = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots + \epsilon)\), where \((Y\)) is normally distributed.
Logistic Regression (binomial Distribution)
- Response Variable: Binary (0 or 1)
- Link Function: Logit (\((g(\mu) = \log(\frac{\mu}{1-\mu})\)))
- Example: Predicting whether a customer will buy a product (yes/no) based on age, income, etc.
- Formula: \((\log(\frac{p}{1-p}) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots\)), where (\(p\)) is the probability of the event occurring.
Poisson Regression (Poisson Distribution)
- Response Variable: Count data (non-negative integers)
- Link Function: Log (\((g(\mu) = \log(\mu)\)))
- Example: Predicting the number of insurance claims in a year based on driver age, vehicle type, etc.
- Formula: \((\log(\lambda) = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots)\), where \((\lambda)\) is the expected count.
Gamma Regression (Gamma Distribution)
- Response Variable: Continuous and positive
- Link Function: Inverse (\((g(\mu) = \frac{1}{\mu}\)))
- Example: Predicting the time until failure of a machine based on temperature, pressure, etc.
- Formula: \((\frac{1}{\mu} = \beta_0 + \beta_1 X_1 + \beta_2 X_2 + \ldots)\), where (\(\mu\)) is the mean of the response variable.
Generalized Linear Models
Examples of GLMs
Logistic Regression Example:
- Scenario: A marketing team wants to predict whether a customer will buy a product.
- Variables: Customer age, income, and previous purchase history.
- Model: \((\log(\frac{p}{1-p}) = \beta_0 + \beta_1 \text{Age} + \beta_2 \text{Income} + \beta_3 \text{History}\))
- Interpretation: The coefficients (_1, _2, _3) indicate how each predictor affects the log odds of making a purchase.
Poisson Regression Example:
- Scenario: An insurance company wants to predict the number of claims a policyholder will file.
- Variables: Age of the policyholder, type of vehicle, and driving experience.
- Model: \((\log(\lambda) = \beta_0 + \beta_1 \text{Age} + \beta_2 \text{VehicleType} + \beta_3 \text{Experience}\))
- Interpretation: The coefficients \((\beta_1, \beta_2, \beta_3)\) indicate how each predictor affects the expected number of claims.
Gamma Regression Example:
- Scenario: A manufacturing company wants to predict the lifetime of a machine part.
- Variables: Operating temperature, pressure, and usage frequency.
- Model: \((\frac{1}{\mu} = \beta_0 + \beta_1 \text{Temperature} + \beta_2 \text{Pressure} + \beta_3 \text{Frequency})\)
- Interpretation: The coefficients \((\beta_1, \beta_2, \beta_3)\) indicate how each predictor affects the inverse of the expected lifetime.
Non-parametric regression
Regression with trees
There are many methodologies for constructing regression trees but one of the oldest is known as the classification and regression tree (CART) approach.
Basic regression trees partition a data set into smaller subgroups and then fit a simple constant for each observation in the subgroup. The partitioning is achieved by successive binary partitions (aka recursive partitioning) based on the different predictors.
Regression with trees
As a simple example, consider a continuous response variable \(y\) with two covariates \(x_1,x_2\) and the support of \(x_1,x_2\) partitioned into three regions. Then we write the tree regression model for \(y\) as:
\[ \hat{y} = \hat{f}(x_1,x_2)=\sum_{i=1}^{3}c_1\times I_{(x_1,x_2)\in R_i} \]
Tree algorithms differ in how they grow the regression tree, i.e. partition the space of the covariates.
Regression with trees
All partitioning of variables is done in a top-down, greedy fashion. This just means that a partition performed earlier in the tree will not change based on later partitions. In general the partitions are made to minimize following objective function (support initially partitioned into 2 regions, i.e. a binary tree):
\[ \text{SSE}=\left\{ \sum_{i\in R_{1}}\left(y_{i}-c_{i}\right)^{2}+\sum_{i\in R_{2}}\left(y_{i}-c_{i}\right)^{2}\right\} \]
Regression with trees
Having found the best split, we repeat the splitting process on each of the two regions.
This process is continued until some stopping criterion is reached. What typically results is a very deep, complex tree that may produce good predictions on the training set, but is likely to overfit the data, particularly at the lower nodes.
By pruning these lower level nodes, we can introduce a little bit of bias in our model that help to stabilize predictions and will tend to generalize better to new, unseen data.
Regression with trees
As with penalized linear regression, we can use a complexity parameter \(\alpha\) to penalize the number of terminal nodes of the tree (\(T\)), like the lasso \(L_1\) norm penalty, and find the smallest tree with lowest penalized error, i.e. the minimizing the following objective function:
\[ \text{SSE}+\alpha\left|T\right| \]
Regression with trees
Strengths
- They are very interpretable.
- Making predictions is fast; just lookup constants in the tree.
- Variables importance is easy; those variables that most reduce the SSE.
- Tree models give a non-linear response; better if the true regression surface is not smooth.
- There are fast, reliable algorithms to learn these trees.
Weaknesses
- Single regression trees have high variance, resulting in unstable predictions (an alternative subsample of training data can significantly change the terminal nodes).
- Due to the high variance single regression trees have poor predictive accuracy.
Regression with trees (Bagging)
As mentioned, single tree models suffer from high variance. Although pruning the tree helps reduce this variance, there are alternative methods that actually exploite the variability of single trees in a way that can significantly improve performance over and above that of single trees. Bootstrap aggregating (bagging) is one such approach.
Bagging combines and averages multiple models. Averaging across multiple trees reduces the variability of any one tree and reduces overfitting, which improves predictive performance.
Regression with trees (Bagging)
Bagging combines and averages multiple tree models. Averaging across multiple trees reduces the variability of any one tree and reduces overfitting, improving predictive performance.
Regression with trees (Bagging)
Bagging follows three steps:
- Create \(m\) bootstrap samples from the training data. Bootstrapped samples allow us to create many slightly different data sets but with the same distribution as the overall training set.
- For each bootstrap sample train a single, unpruned regression tree.
- Average individual predictions from each tree to create an overall average predicted value.
Regression with trees (Bagging)
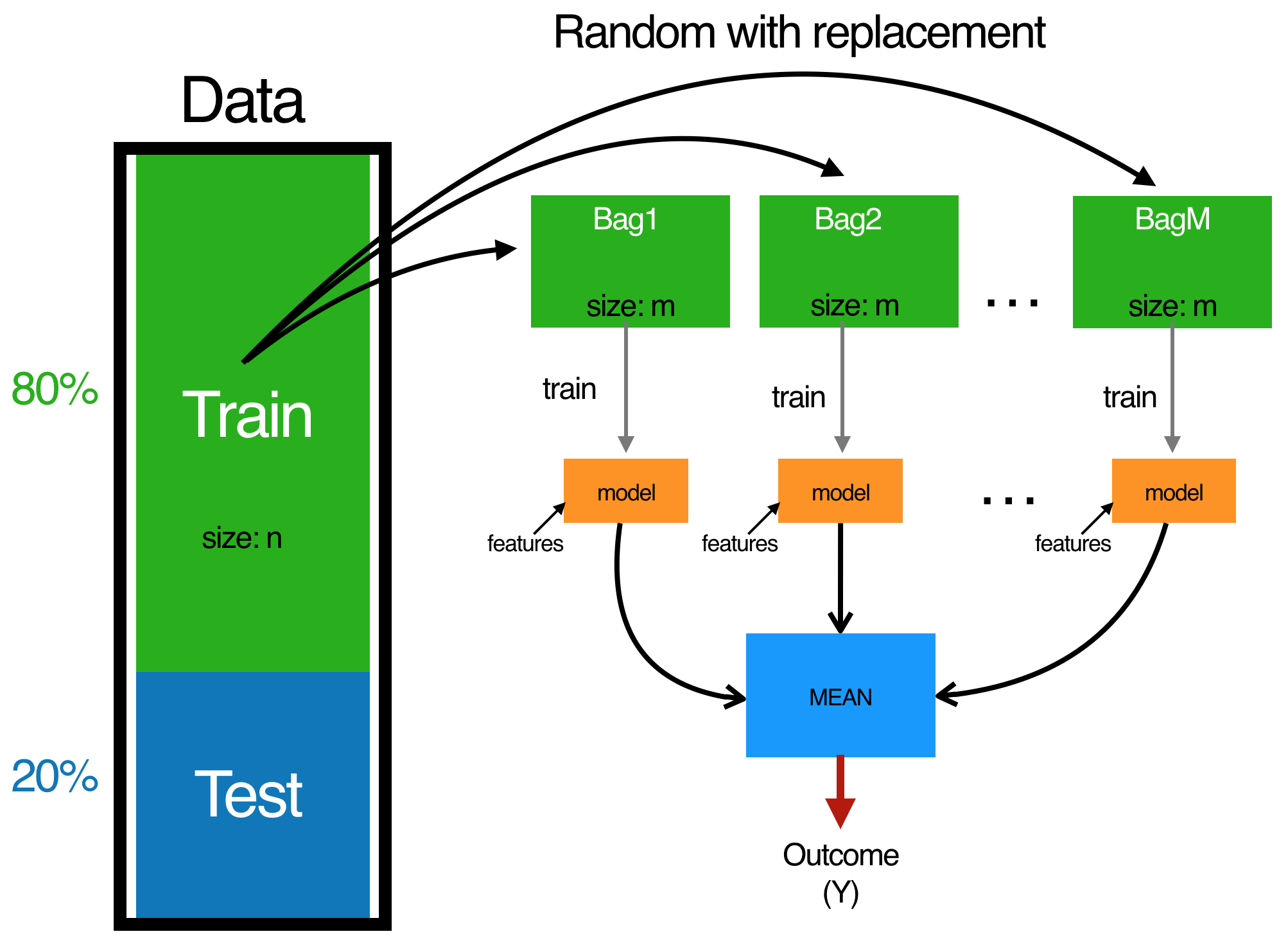
Fig: The bagging process.
Regression with a random forest
Bagging trees introduces a random component into the tree building process that reduces the variance of a single tree’s prediction and improves predictive performance. However, the trees in bagging are not completely independent of each other since all the original predictors are considered at every split of every tree.
So trees from different bootstrap samples typically have similar structure to each other (especially at the top of the tree) due to underlying relationships. They are correlated.
Regression with a random forest
Tree correlation prevents bagging from optimally reducing the variance of the predictive values. Reducing variance further can be achieved by injecting more randomness into the tree-growing process. Random forests achieve this in two ways:
- Bootstrap: similar to bagging - each tree is grown from a bootstrap resampled data set, which somewhat decorrelates them.
- Split-variable randomization: each time a split is made, the search for the split variable is limited to a random subset of \(m\) of the \(p\) variables.
Regression with a random forest
For regression trees, typical default values used in split-value randomization are \(m=\frac{p}{3}\) but this should be considered a tuning parameter.
When \(m=p\), the randomization amounts to using only step 1 and is the same as bagging.
Regression with a random forest
Strengths
- Typically have very good performance
- Remarkably good “out-of-the box” - very little tuning required
- Built-in validation set - don’t need to sacrifice data for extra validation
- No pre-processing required
- Robust to outliers
Weaknesses
- Can become slow on large data sets
- Although accurate, often cannot compete with advanced boosting algorithms
- Less interpretable
Regression with gradient boosting
Gradient boosted machines (GBMs) are an extremely popular machine learning algorithm that have proven successful across many domains and is one of the leading methods for winning Kaggle competitions.
Regression with gradient boosting
Whereas random forests build an ensemble of deep independent trees, GBMs build an ensemble of shallow and weak successive trees with each tree learning and improving on the previous. When combined, these many weak successive trees produce a powerful “committee” that are often hard to beat with other algorithms.
Regression with gradient boosting
The main idea of boosting is to add new models to the ensemble sequentially. At each particular iteration, a new weak, base-learner model is trained with respect to the error of the whole ensemble learnt so far.

Sequential ensemble approach.
Regression with gradient boosting
Boosting is a framework that iteratively improves any weak learning model. Many gradient boosting applications allow you to “plug in” various classes of weak learners at your disposal. In practice however, boosted algorithms almost always use decision trees as the base-learner.
Regression with gradient boosting
A weak model is one whose error rate is only slightly better than random guessing. The idea behind boosting is that each sequential model builds a simple weak model to slightly improve the remaining errors. With regards to decision trees, shallow trees represent a weak learner. Commonly, trees with only 1-6 splits are used.
Regression with gradient boosting
Combining many weak models (versus strong ones) has a few benefits:
- Speed: Constructing weak models is computationally cheap.
- Accuracy improvement: Weak models allow the algorithm to learn slowly; making minor adjustments in new areas where it does not perform well. In general, statistical approaches that learn slowly tend to perform well.
- Avoids overfitting: Due to making only small incremental improvements with each model in the ensemble, this allows us to stop the learning process as soon as overfitting has been detected (typically by using cross-validation).
Regression with gradient boosting
Here is the algorithm for boosted regression trees with features \(x\) and response \(y\):
- Fit a decision tree to the data: \(F_1(x)=y\),
- We then fit the next decision tree to the residuals of the previous: \(h_1(x)=y−F_1(x)\)
- Add this new tree to our algorithm: \(F_2(x)=F_1(x)+h_1(x)\),
- Fit the next decision tree to the residuals of \(F_2: h_2(x)=y−F_2(x)\),
- Add this new tree to our algorithm: \(F_3(x)=F_2(x)+h_1(x)\),
- Continue this process until some mechanism (i.e. cross validation) tells us to stop.
XGBoost Example
XGBoost is short for eXtreme Gradient Boosting package.
While the XGBoost model often achieves higher accuracy than a single decision tree, it sacrifices the intrinsic interpretability of decision trees. For example, following the path that a decision tree takes to make its decision is trivial and self-explained, but following the paths of hundreds or thousands of trees is much harder.
We will work with XGBoost in today’s lab.
Kernel Regression
Kernel Regression is a non-parametric technique in machine learning used to estimate the relationship between a dependent variable and one or more independent variables.
Unlike linear regression, Kernel Regression does not assume a specific form for the relationship between the variables. Instead, it uses a weighted average of nearby observed data points to make predictions.
Kernel Regression
- Select a Kernel Function:
- Choose a kernel function that will determine how weights are assigned to nearby data points. The Gaussian kernel is a common choice, where weights decrease with distance according to a normal distribution.
- Choose a Bandwidth:
- Decide on the bandwidth parameter that will control the spread of the kernel function. This affects the smoothness of the regression curve.
- Compute Weights:
- For each point where you want to estimate the dependent variable, compute the weights for all observed data points using the kernel function.
- Calculate Weighted Average:
- Use the weights to compute a weighted average of the dependent variable values, giving more influence to points closer to the point of interest.
Kernel Regression: example
Code
> #Kernel regression
> # from https://towardsdatascience.com/kernel-regression-made-easy-to-understand-86caf2d2b844
> Kdata <-
+ tibble::tibble(
+ Area = c(11,22,33,44,50,56,67,70,78,89,90,100)
+ , RiverFlow = c(2337,2750,2301,2500,1700,2100,1100,1750,1000,1642, 2000,1932)
+ )
>
> #function to calculate Gaussian kernel
> gausinKernel <- function(x,b){exp(-0.5 *(x/b)^2)/(sqrt(2*pi))}
> #plotting function
> plt_fit <- function(bandwidth = 10, support = seq(5,110,1)){
+ tibble::tibble(x_hat = support) |>
+ dplyr::mutate(
+ y_hat =
+ purrr::map_dbl(
+ x_hat
+ , (
+ \(x){
+ K <- gausinKernel(Kdata$Area-x, bandwidth)
+ sum( Kdata$RiverFlow * K/sum(K) )
+ })
+ )
+ ) |>
+ ggplot(aes(x=x_hat, y=y_hat)) +
+ geom_line(color="blue") +
+ geom_point(data = Kdata, aes(x=Area, y=RiverFlow), size=4, color="red") +
+ labs(title = "Kernel regression", subtitle = stringr::str_glue("bandwith = {bandwidth}; data = red | fit = blue") ) +
+ theme_minimal()
+ }


Kernel Regression:
Advantages of Kernel Regression
- Flexibility: Can capture complex, non-linear relationships between variables.
- No Assumptions: Does not require the assumption of a specific functional form for the relationship.
Disadvantages of Kernel Regression
- Computationally Intensive: Can be slow, especially with large datasets, since it requires calculating weights for all data points for each estimate.
- Choice of Parameters: The results can be sensitive to the choice of kernel function and bandwidth, requiring careful tuning.
Regression with neural nets
Regression with neural nets involves using artificial neural networks (ANNs) to predict a continuous output variable based on one or more input variables. Neural nets are powerful, flexible models that can capture complex relationships and patterns in the data.
Regression with ANNs: Components
- Neurons:
- The building blocks of neural networks. Each neuron takes an input, processes it, and passes the output to the next layer.
- Layers:
- Input Layer: Receives the input data.
- Hidden Layers: Intermediate layers that process the input data through neurons. There can be one or more hidden layers.
- Output Layer: Produces the final prediction.
- Weights and Biases:
- Each connection between neurons has a weight, which adjusts the strength of the signal.
- Each neuron has a bias, which adjusts the output along with the weighted sum of inputs.
Regression with ANNs: Components
- Activation Functions:
- Functions applied to the output of each neuron in hidden layers to introduce non-linearity. Common activation functions include ReLU (Rectified Linear Unit), sigmoid, and tanh.
- Loss Function:
- Measures the difference between the predicted output and the actual output. For regression tasks, common loss functions include Mean Squared Error (MSE) and Mean Absolute Error (MAE).
- Optimization Algorithm:
- Adjusts the weights and biases to minimize the loss function. The most common optimization algorithm is Gradient Descent and its variants like Adam.
Regression with ANNs: Algorithm
- Forward Propagation:
- Input data is passed through the network, layer by layer, with each neuron applying its weights, bias, and activation function, until the output layer produces the prediction.
- Loss Calculation:
- The loss function calculates the error between the predicted output and the actual target value.
- Backward Propagation:
- The network uses the error to adjust the weights and biases. This involves calculating the gradient of the loss function with respect to each weight and bias (using the chain rule), and then updating the weights and biases to reduce the error.
- Iterative Training:
- The process of forward propagation, loss calculation, and backward propagation is repeated for many iterations (epochs) until the loss converges to a minimum value.
Regression with ANNs:
Advantages of ANNs for Regression
- Flexibility: Can model complex, non-linear relationships between inputs and outputs.
- High Performance: Can achieve high accuracy with sufficient data and proper tuning.
- Feature Learning: Automatically learns relevant features from raw input data.
Disadvantages of ANNs for Regression
- Computationally Intensive: Requires significant computational resources.
- Data Hungry: Needs a large amount of training data to perform well.
- Complexity: Requires careful tuning of hyperparameters (e.g., number of layers, neurons, learning rate) and can be prone to overfitting if not properly regularized.
Regression with neural nets
Architecture of an ANN

Single layer NN architecture
Regression with neural nets

Common Activation Functions
Regression with ANNs: example
Code
> set.seed(500)
>
> # Boston dataset from MASS
> data <- MASS::Boston
>
> # Normalize the data
> maxs <- data %>% dplyr::summarise_all(max) %>% as.matrix() %>% as.vector()
> mins <- data %>% dplyr::summarise_all(min) %>% as.matrix() %>% as.vector()
> data_scaled <- data %>%
+ scale(center = mins, scale = maxs - mins) %>%
+ tibble::as_tibble()
>
> # Split the data into training and testing set
> data_split <- data_scaled %>% rsample::initial_split(prop = .75)
> # extracting training data and test data as two seperate dataframes
> data_train <- rsample::training(data_split)
> data_test <- rsample::testing(data_split)
>
> nn <- data_train %>%
+ neuralnet::neuralnet(
+ medv ~ .
+ , data = .
+ , hidden = c(5, 3)
+ , linear.output = TRUE
+ )
>
> # Predict on test data
> pr.nn <- neuralnet::compute( nn, data_test %>% dplyr::select(-medv) )
>
> # Compute mean squared error
> pr.nn_ <-
+ pr.nn$net.result *
+ (max(data$medv) - min(data$medv)) +
+ min(data$medv)
> test.r <-
+ data_test$medv *
+ (max(data$medv) - min(data$medv)) +
+ min(data$medv)
> MSE.nn <- sum((test.r - pr.nn_)^2) / nrow(data_test) Regression with neural nets


Recap
Today we worked though a parametric and non-parametric regression methods that are useful for predicting a value given a set of covariates.
Next week we will look in detail at the
tidymodelspackage which will give a way to develop a workflow for fitting and comparing our models across different feature sets.